rfcindex backend

Overview:
In this post I provide a brief tour of the rfcindex backend api's current state, chart out some possible next steps, and ideally recenter our thinking to maximize overall impact for the project. I had one overarching goal in context of scaffolding the backend and that was to make it incredibly easy to survey a plethora of applications of prompt engineering strategies spanning a broad spectrum of use cases. Prompting is an incredibly accessible means of cyphening tremendous work out of llms without sprawling into the territory of investing in one's own llms or exhaustive fine-tuning investments. Its well documented here (opens in a new tab), here (opens in a new tab), and here (opens in a new tab) just to name a few. Some tangential topics I briefly touch on are around general design decisions that are intended to compound gracefully overtime as our coverage of use cases expands rapidly and free time to contemplate the rudimentary gradually whithers.
Schema Alignment:
The OpenAPI Spec is one of my favorite pillars of this project setup. Its the pleasant birds eye view, a delightful retro, especially after investing substantial time into the repo and accruising 4-5 routes filled with new functionality. The spec for this project has some high centrality endpoints, the core group of services/offerings if you will. 1) Firstly we'll cover search, I'm kind of relieved this endpoint came into fruition the way it did.
During the design of search, I was reluctant because initially it meant the undertaking of implementing embeddings based vector search, testing, and unearthing how impactful or potentially unnecessary the endeavor would turn out to be. But after enough research I took a detour that ended up being delightfully frugal, and came with high availability.
My design consists of utilizing the official datatracker api endpoints that facilitate search
on their website + some structured dom marshalling. I opted to proxy the ietf's datatracker search
page in a headless manner which utilizes strictly pre-existing search capacity. The /search/query/ietf
endpoint takes the SearchRequestDTO containing the following request payload:
{
"query": "dns",
"rfc_text": "",
"url": "",
"context": ""
}and responds with the following results:
{
"results": [
[],
[
"RFC 4641",
"ASCII, PDF, HTML, HTML with inline errata",
"DNSSEC Operational Practices",
"O. Kolkman, R. Gieben",
"September 2006",
"Errata, Obsoletes RFC 2541, Obsoleted by RFC 6781",
"Informational",
"https://www.rfc-editor.org/info/rfc4641",
"https://www.rfc-editor.org/rfc/rfc4641.txt",
"https://www.rfc-editor.org/errata/rfc4641"
],
[
"ABSTRACT",
"This document describes a set of practices for operating the DNS with\r\nsecurity extensions (DNSSEC). The target audience is zone\r\nadministrators deploying DNSSEC.\r\n\r\nThe document discusses operational aspects of using keys and\r\nsignatures in the DNS. It discusses issues of key generation, key\r\nstorage, signature generation, key rollover, and related policies.\r\n\r\nThis document obsoletes RFC 2541, as it covers more operational\r\nground and gives more up-to-date requirements with respect to key\r\nsizes and the new DNSSEC specification. This memo provides information for the Internet community."
],
[
"KEYWORDS",
"dns, domain name space, security extensions, zone administrator, DNS-SOC, cryptology, resource records, rrs"
],
[
"RFC 6781",
"ASCII, PDF, HTML, HTML with inline errata",
"DNSSEC Operational Practices, Version 2",
"O. Kolkman, W. Mekking, R. Gieben",
"December 2012",
"Errata, Obsoletes RFC 4641",
"Informational",
"https://www.rfc-editor.org/info/rfc6781",
"https://www.rfc-editor.org/rfc/rfc6781.txt",
"https://www.rfc-editor.org/errata/rfc6781"
],
[
"ABSTRACT",
"This document describes a set of practices for operating the DNS with\r\nsecurity extensions (DNSSEC). The target audience is zone\r\nadministrators deploying DNSSEC.\r\n\r\nThe document discusses operational aspects of using keys and\r\nsignatures in the DNS. It discusses issues of key generation, key\r\nstorage, signature generation, key rollover, and related policies.\r\n\r\nThis document obsoletes RFC 4641, as it covers more operational\r\nground and gives more up-to-date requirements with respect to key\r\nsizes and the DNSSEC operations."
],
[
"KEYWORDS",
"DNSSEC, operational, key rollover"
]
]
}From first glance, this seems really unsustainable but I would argue it propells certain parts of the system's development while closely steering the dataflow into alignment with notarized datatracker api endpoints. No performance drawbacks, very little code complexity or bespoke customization, and search that moves the needle forward - a frugally innovative proof of concept for search that defers the many levels of complexity around vector based search.
The next major api feature I wanted to outline was the debut of QA related endpoints. Our first runner up is the baseline single thread contigious closed document QA'ing endpoint. For its endpoint design I wanted to cultivate design inspiration from the platformers of major gen ai vendors. Ideally, with enough iterations I could design a schema that acts as a common denominator that resembles the infamous completion object (opens in a new tab).
The most pragmatic approach to designing this portion of the api without compromise is to make it identical and compatible
with a whole host of llm providers, putting an emphasis on resembling the most commonly known vendor first. With mild changes
to the response schema, the /qa/single/contigious endpoint accepts the following payload:
{
"context":"https://www.rfc-editor.org/rfc/rfc6159.txt",
"query":"What knowledge will I gain about the 3GPP Wireless LAN (WLAN) Access Architecture upon reading this RFC?",
"invocation_mode": "SINGLE",
"invocation_filter": "mistral"
}and in return the api sends:
{
"completion": {
"id": "mistralai/Mixtral-8x22B-Instruct-v0.1-80bc338d-3787-44c9-ae5c-3a60d0220cfb",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": {
"text_offset": null,
"token_logprobs": null,
"tokens": null,
"top_logprobs": null
},
"text": " The text you have provided appears to be the content of RFC 6159, the \"Diameter Explicit Routing\" IETF standard, which describes a mechanism to enable specific Diameter proxies to maintain their position in the path of all message exchanges constituting a Diameter session. I can assist in answering questions or provide more information on the content. Please let me know if you have any specific inquiries."
}
],
"created": 1714465650,
"model": "mistralai/Mixtral-8x22B-Instruct-v0.1",
"object": "text_completion",
"system_fingerprint": null,
"usage": {
"completion_tokens": 94,
"prompt_tokens": 11183,
"total_tokens": 11277
}
},
"query": "What knowledge will I gain about the 3GPP Wireless LAN (WLAN) Access Architecture upon reading this RFC?",
"context": "https://www.rfc-editor.org/rfc/rfc6159.txt"
}Throughout the project I default to leaving things backwards compatible for the sake of iteration speed, so its worth pointing out that in production, a more formal schema evolution policy is more suitable. The front end now routinely consumes this uninterrupted by the pace or direction of platform api related progress.
A broader index-view of all current-state endpoints are depicted below + the OpenAPI spec file is publically viewable in the repo (opens in a new tab):
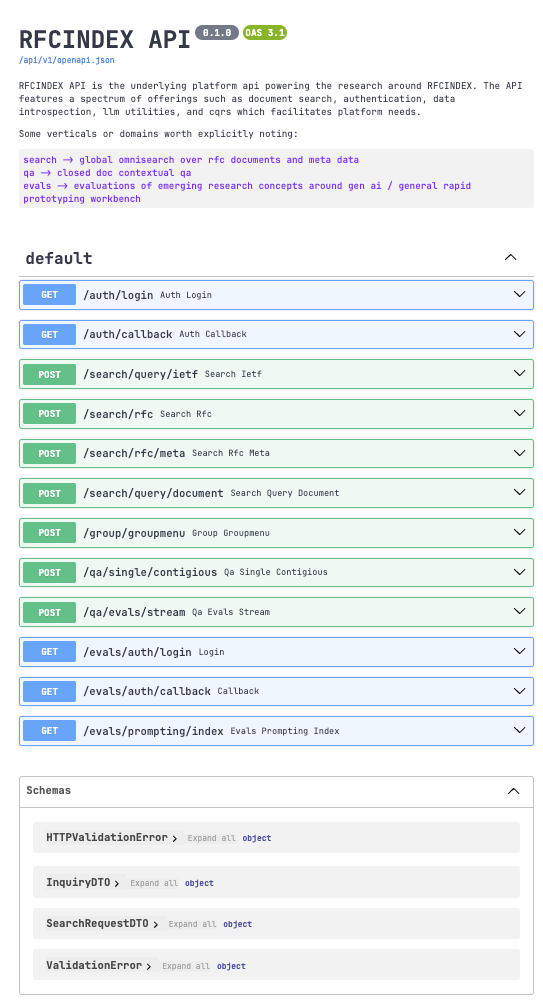
Design Patterns:
I've always enjoyed being acqaunted with abstract concepts, distant theory that seems to resonate with parallel universes, code that exists in a realm foreign to mine, irrelevant to the esoteric pot holes next to my feet. Its intriguing to read, but rarely ever translates to my field of view, actual projects come bearing very real friction far more nuanced than the controlled experiments used to illustrate when any given pattern will be suitable for the problem at hand. Ergo, I'm premeditating the same phenomena for this project and reaching for something low overhead and earthly. The "Module Pattern", the "Unit of Work Pattern", the "Repository", are a few aliases I've seen for this pattern. You can find more about it here (opens in a new tab), and here (opens in a new tab). But in its most pedestrian form, I think the pattern instructs to "strategically collocate constituent parts that make up a larger thing". Thus far I've rarely found myself in some technical labrynth that warrents designing some grandiose blueprint promising to reach some mythical idea future state. This pattern is one that is gracefully general and helps establish healthy convention and routine.
- routes - fast api routing jargon
- dto(s) - data transfer objects, i.e. a means of removing excess information leading up to transmission
- dao(s) - data access objects, anything that acts as a portal to retrieving state
- services - utility classes or atomic functions that interact with apis or foreign derived information sources
- util(s) - repetitive things that needn't be repeated
Its also worth mentioning that not every unit of work requires that all 5 categories of files must exist. In many places I play it by ear and if I feel like introducing dtos for a particular unit of work is extranous, I simply omit. If you're a visual learner then a gentle example can be used to illustrate the idea. Take the following file structure for example:
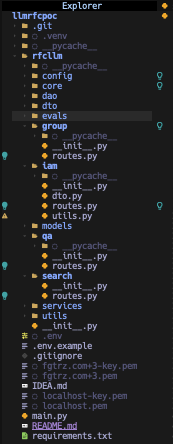
Here the folders group, iam, qa, and search can be referred to as units of work. Each unit of work can potentially contain the 5 categories of files I mentioned earlier - these files are packaged under one label serving some given purpose. Here's a homogenized illustration that can convey the underlying message:
unitofwork1/
- routes.py
- dtos.py
- daos.py
- services.py
- utils.py
- __init__.py
unitofwork2/
- routes.py
- dtos.py
- daos.py
- services.py
- utils.py
- __init__.py
unitofwork3/
- routes.py
- dtos.py
- daos.py
- services.py
- utils.py
- __init__.pySometimes design requires skillful improvising. Consider the following scenario:
unitofwork1/
- ...
unitofwork2/
- ...
unitofwork3/
- ...
unitofwork4/
- ...
- utils.py
utils/
- __init__.py
- index.py
- ...Modules 1, 2, 3, all have needs for a utility present in utils/index.py, but said utility isn't relevant to module 4. Borrowing from practices such as lifting state up, or factoring constants out of polynomials, I opt for alloting a utility module that has global scope. All other modules interested in harnessing this functionality can summon it at their own disgretion and code reuse + cleanliness is maintained. No drama, frugal design, and an urge to keep it moving.
Production Environment:
A couple things I prioritized when planning where this api will live once I put everything on the grid:
- Universal devops workflow / tasks which translate well to-fro anywhere. (i.e. I cared about aws/google/azure agnostic nomenclature or taxonomy)
- Minimizes roll-your-own security, but avoiding too many crutches
- Bad things always happen on the internet. Rfcindex needed to gaurd against llm abuse, and militantly defend against violation of any gen ai vendor's moderation and guiding principles.
- Fast workflows (i.e. ssh in, do the dance, send it up, and when-needed roll back)
Ergo the answer was: a linux kitchen living on ec2. In nascent stages this meant a publically accessible instance that ran the FastAPI app in daemon fashion + exposed it to the internet for authenticated/authorized invocation, but in future state, this could mean an apache airflow system which scaffolds a csv-only database service in this ec2 alongside the FastAPI app, and then perhaps a mesh of proxy servers / load balancers. TLDR: the fastest route to get the api in the air, and compromise little to no creative control around production architecture - hence a linux container that can harbor anything.
There was of course the looming necessity for a contingency plan, i.e. when the need for aws dissipates into thin air, how quickly can I migrate and redeploy? Reasonably fast solely due to depending on something omnipotent like a linux/ubuntu distro based virtual environment. I mean gcp quite literally has ec2-like clones of product offerrings, alongside 5-6 players.
Now we're ready to refocus on the actual platform and exploratory features.
Core:
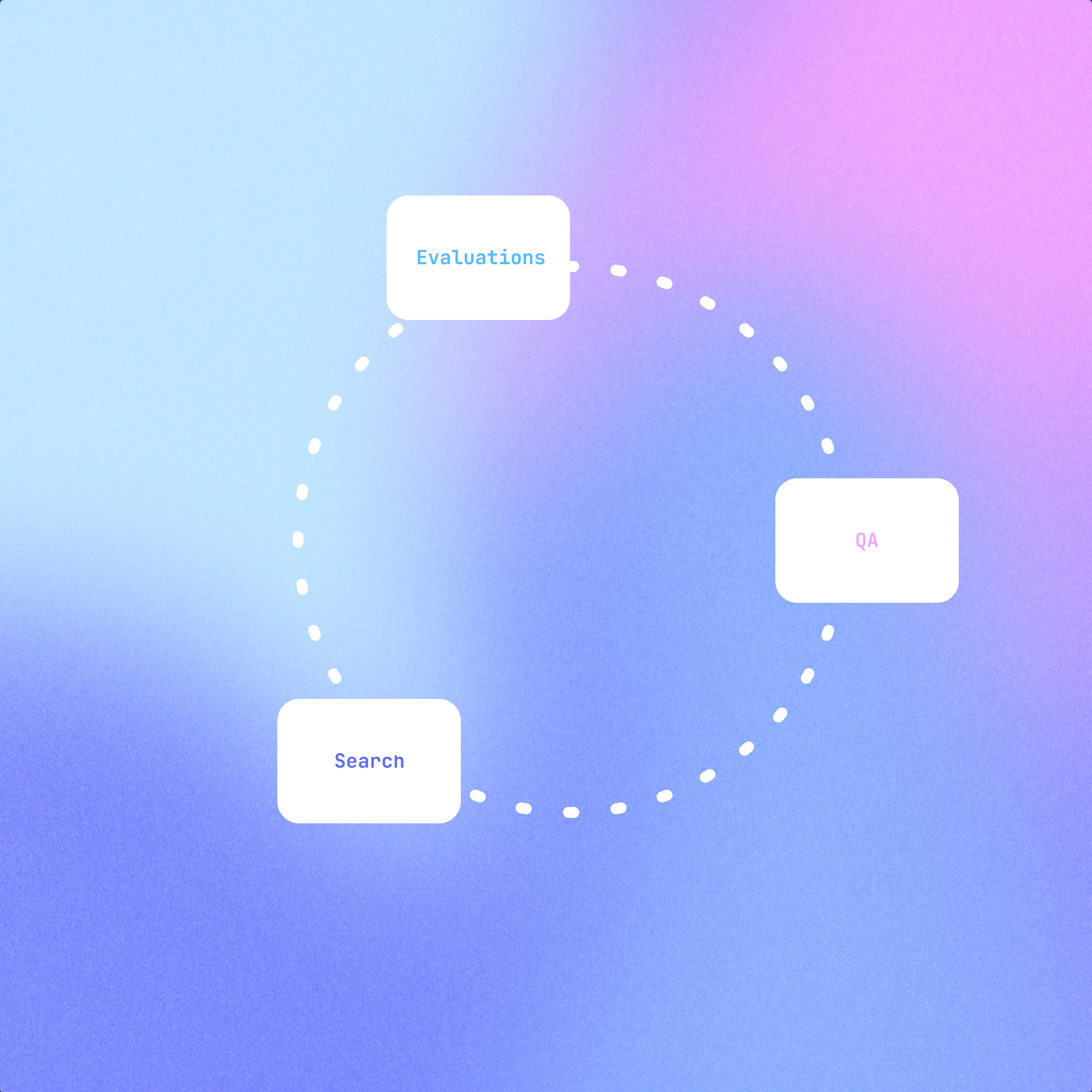
The "core" of RFCINDEX is my best attempt at designing, cross-pollinating, and juxtaposing these efforts into a graceful platform. Search consists of querying ietf apis for RFCs, QA offers mono-thread closed domain question and answering pertinent to the RFC in question, and Evaluations is the portal to fostering long-term expansion of RFCINDEX. By now the research corpus around gen ai flowing frequently, document search is not uncharted territory, but evaluations are the bleeding edge.
Some context and prior art that inspired the decision to explore evaluations:
From further examination of The Prompting Guide (opens in a new tab), we see the collection of sensible starting points for evaluating different ways to reframe and reapply the techniques in the realm of RFC documents. My tentative scope of work entails operationalizing the following features:
{
"zeroshot": "Zero-shot Prompting",
"fewshot": "Few-shot Prompting",
"cot": "Chain-of-Thought Prompting",
"consistency": "Self-Consistency",
"knowledge": "Generate Knowledge Prompting",
"prompt_chaining": "Prompt Chaining",
"tot": "Tree of Thoughts",
"rag": "Retrieval Augmented Generation",
"art": "Automatic Reasoning and Tool-use",
"ape": "Automatic Prompt Engineer",
"activeprompt": "Active-Prompt",
"dsp": "Directional Stimulus Prompting",
"pal": "Program-Aided Language Models",
"react": "ReAct",
"reflexion": "Reflexion",
"multimodalcot": "Multimodal CoT",
"graph": "Graph Prompting"
}And mapping them to focused atomic functions residing in /evals/prompting_evals.py. Once
we've reached that milestone, the functions can be utilized by the larger system to promote
sophisticated discovery and comprehension of RFC(s).
You can follow along as I regularly inch closer to assembling this api here (opens in a new tab). My hunches suggest that llm swarms and botnets will most probably release far more sophisticated applications demonstrating what I'm aspiring to accomplish using RFCINDEX, but I'm eager to soak up whatever wisdom I can interim. If you've read this far and are wondering why I'm still hand crafting bespoke gen ai application features in 2024 instead of dispatching an agentic swarm network to breath life into my ideas via code gen, I want to savor what this era feels like. The days of engineering the way we once knew are numbered and I want to expunge every opportunity to cultivate craftsmanship before redefining core aspects of how I build going forward. Tldr: this might be one of the last times I whiteboard some project idea, and rush to bring it to life, or hand craft a platform api in Python, so I will milk all the joy I can out of this experience.
This pretty much somes up what I wanted to touch on for this entry, now I close with the suspense derived from trying to answer the following: how might we curate, and combine the optimal assembly of prompting techniques, such that it enriches end user engagement and comprehension of RFC(s)? The real excitement commences once we've laid the foundations for accomplishing the bare-minimum (e.g. user query in, and thoughtful generative agent response out), the vast unknown of picking a prompting strategy, experimenting with orchestration details, re-purposing discoveries from the wild, and centering everything around the simple goal of enriching the journey through an RFC. Stay tuned if you've followed along thus far and care to see where this takes us!